Rules to Better Business Intelligence - 7 Rules
Need professional Enterprise Reporting and BI solutions for your business? Check SSW's Enterprise Reporting Consulting page.
It’s easy to capture lots of telemetry from your software; everything from exceptions to usage statistics. But do you know what to do with it and how to interpret what this data is telling you? That’s the difference between information, intelligence, and wisdom.
Your data is a potentially valuable asset and it should be working hard for you. Let's look at a hypothetical example involving adding a new feature to SSW Rewards that allows users to upload a custom profile pic. We want to know whether users are more likely to discover and adopt new features when using light mode vs dark mode. So we conduct some A/B testing to see which is working better.
Level 1: Information
Information tells you what happened. Lots of data is available and its easy to record it all now in a service like App Insights, but at this point it’s only information and you need to turn it into something useful for it to have value.
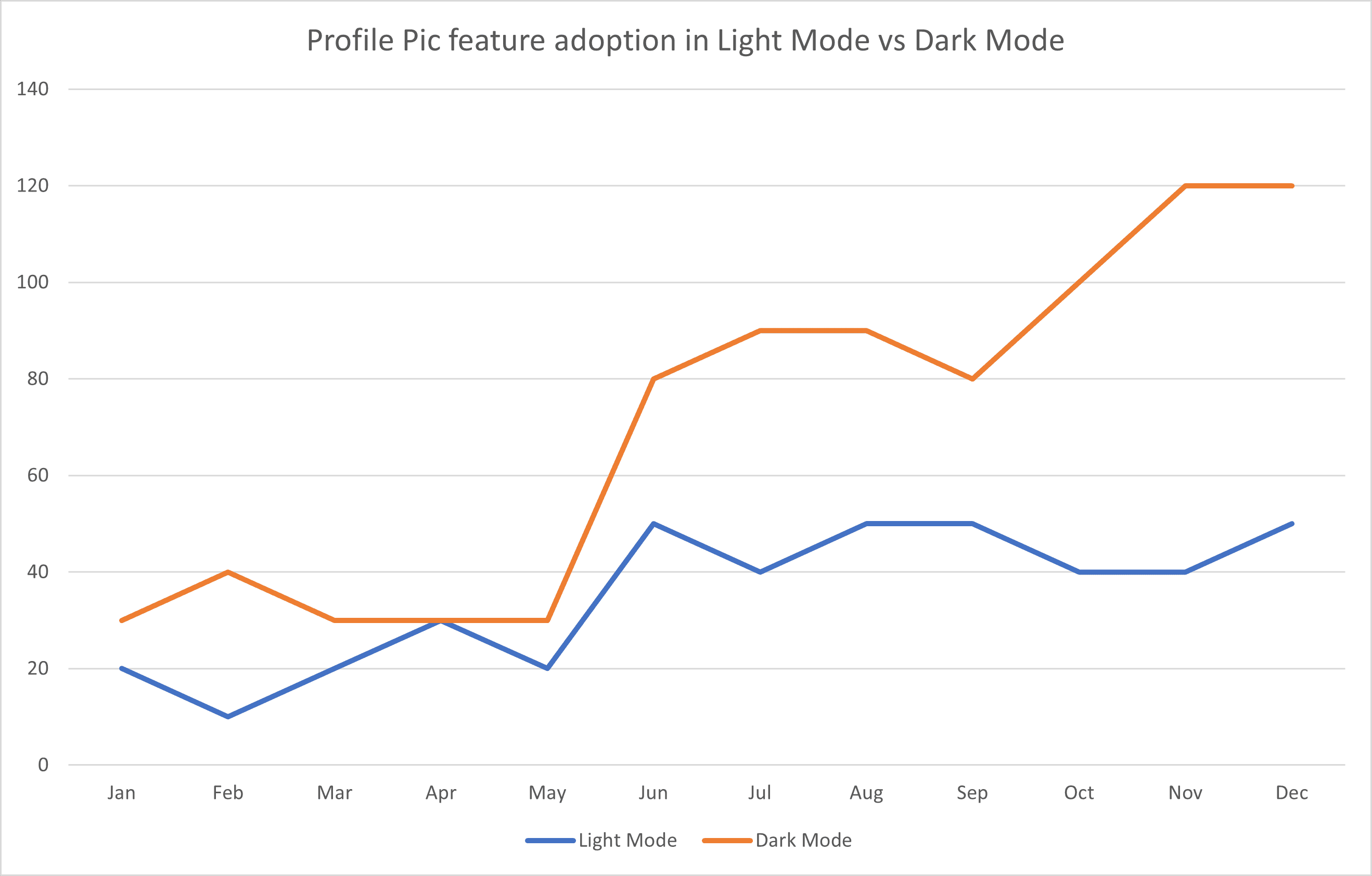
In this hypothetical example, we can see the following information about how many people used the new profile pic feature in light mode and how many used it in dark mode.
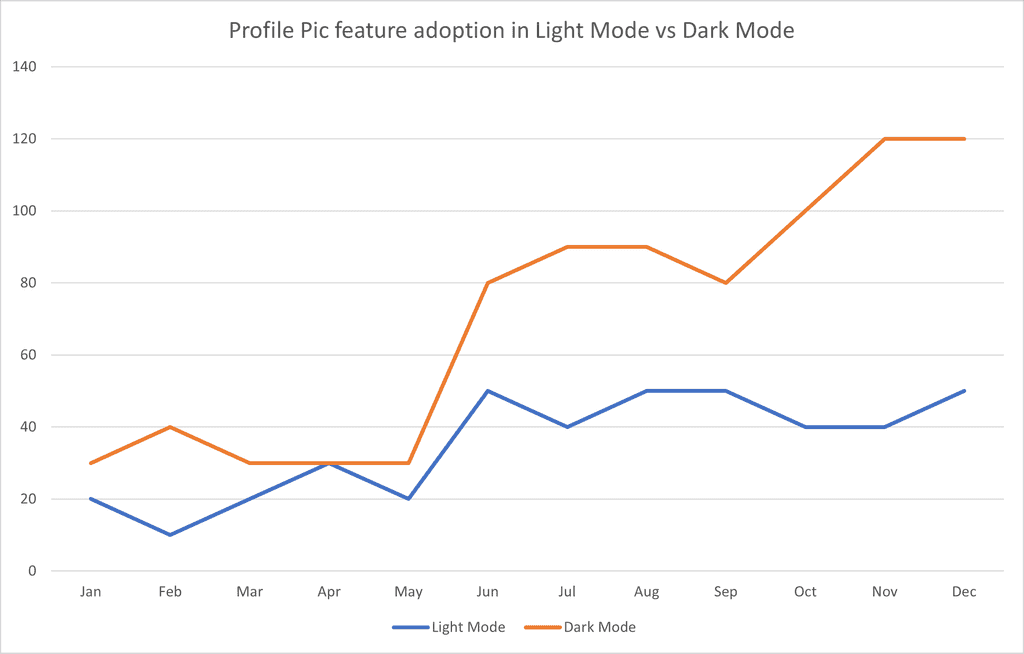
Figure: The results of the A/B testing showing how many people activated the profile pic feature in light mode vs how many activated it in dark mode Level 2: Intelligence
Intelligence tells you why something happened. Having lots of data is awesome, but you should be able to draw meaningful interpretations from that data, or better yet, as your data grows and you know how to recognise patterns in it, have your system draw these automatically and raise alerts about important events.
A simple analysis of the above A/B results shows that significantly more people use the profile picture feature in dark mode than in light mode. However, we can add some context:
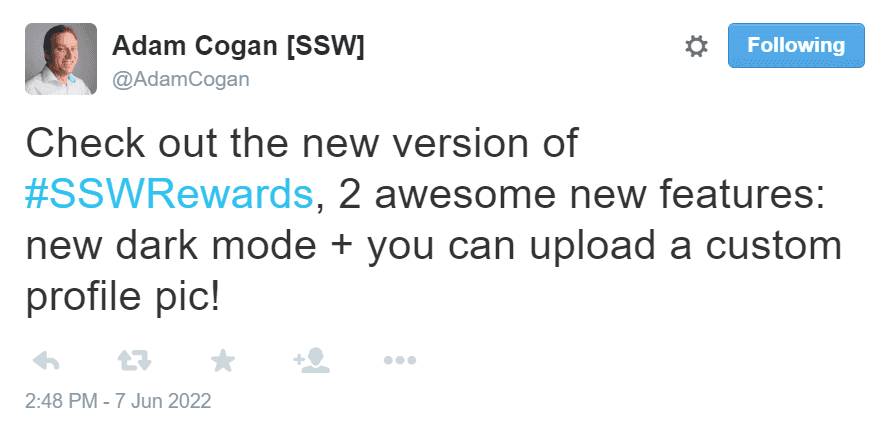
Figure: A hypothetical announcement from SSW Chief Architect Adam Cogan about the new profile picutre feature and the new dark mode feature With this additional context, we can look at the figure above and see that the feature got a boost in both light mode AND dark mode after this tweet. So it seems like the tweet did more to bost adoption of this feature than discoverability in dark mode did.
Level 3: Wisdom
Wisdom tells you what you should do next. The information and intelligence that you are gathering should be usable to make informed decisions about how you should manage your system or business. A good business intelligence system should provide actionable recommendations rather than simply providing information and explanations.
Note: Your business intelligence system could be automated (awesome) but could also be a combination of automated reporting technology as well as human review processes (not as cool, but still better than not interpreting your data).
With the added intelligence above, we can see that social media engagement seems to drive adoption of new features, so we should use this to promote these features when we deliver them. However we can still see that engagement with dark mode seems to be higher, so we shouldn't discount this either.
However, the key gem of wisdom here is to isolate test variables so that we don't skew the results of our A/B testing, or intentionally build multivariate tests as well as the telemetry required to correlate and analyze the data from the different variants.
Examples
Information Intelligence Wisdom Our app service goes offline every day at 3am Increased demand between 2am, and 4am often pushes the system beyond peak capacity Automate your infrastructure to scale out on a schedule to meet increased demand We got 30% fewer clicks from our social media advertising in July than we did in June. In July we diverted advertising budget away from social media platform A to social media platform B. Platform A generates more clicks than platform B Should we focus all our advertising on platform A? No, because while platform B generates fewer clicks, it generates higher quality clicks (i.e. 70% higher conversions than platform A). What is this? It’s a hot dog. Can I eat the hot dog? Yes. Should I eat the hot dog? Probably not. When making reports, charts, and visualizations, it’s important to be consistent with your titles.
Power BI shows "XXX by YYY" (e.g. total earnings by month) rather than "XXX per YYY" and so it’s best to stay with the default and use this throughout your charts.
Figure: Bad example - Using "per" 
Figure: Good example - Using "by" In OLAP (Online Analytical Processing) cubes, dimensions are ways to categorize data. For example, in a sales cube, you might have dimensions for Time, Products, and Geography. Each dimension can have a hierarchy, and the top level is often represented as "All," which aggregates the data across all members of that dimension.
Default Behavior
By default, the top level of each dimension is labeled as "All" followed by the dimension name. For example:
- "All Products" for the Products dimension
- "All Time" for the Time dimension
- "All Geography" for the Geography dimension
This default labelling can be redundant and might not add clarity to the reports generated from these OLAP cubes.
Improve Clarity by Adjusting the 'All Caption'
Simplify and unify the representation of the top level in each dimension to improve the clarity and appearance of reports.
Adjusted Setting: The 'All Caption' property for each dimension is set to "All" without the dimension name.
Dimension Caption: "All Products"
Dimension Caption: "All Time"
Dimension Caption: "All Geography"Figure: Bad example (Before adjustment) - In this scenario, the prefix "All" followed by a space and the dimension name can make reports look cluttered and does not add meaningful information
Dimension Caption: "All"
Figure: Good example (After adjustment) - In the improved scenario, each dimension's top level simply reads "All," eliminating redundancy and making the data presentation cleaner and more straightforward
How to make the change
- Access the properties - In your OLAP cube design tool, locate the properties for each dimension
- Adjust the 'All Caption' - Change the 'All Caption' property from "All [Dimension Name]" to just "All"
- Apply and test - Save your changes and generate a report to ensure that the top level of each dimension now simply reads "All", making the report more aesthetically pleasing and easier to understand
Adjusting the 'All Caption' property in your OLAP cube dimensions simplifies report headings and enhances readability. This minor change can significantly impact the professionalism and clarity of your reporting solutions.
Databases, data warehouses, and data lakes are all essential components of Business Intelligence (BI) systems, but they serve different purposes and have distinct characteristics. Understanding their differences can help organizations make informed decisions about data storage and analysis.
Video: Database vs Data Warehouse vs Data Lake | What is the Difference? (5 min)Basic (video above) - [YouTube: Alex The Analyst] gives a good summary of the differences between the 3 types of data storage.
Advanced - [YouTube: Seattle Data Guy] If you want to go a little deeper, take a look at the video Databases Vs Data Warehouses Vs Data Lakes - What Is The Difference And Why Should You Care? (14 min) which goes into more detail.
Databases
A database is a structured collection of data organized in a specific format, usually in tables with defined relationships between them. Databases are designed for transactional processing and are optimized for quick retrieval and updates of individual records. They excel at handling real-time, operational data and are commonly used for applications such as customer relationship management (CRM) or inventory management. Databases provide strong data consistency and enforce data integrity through predefined rules and constraints. However, they may have limited scalability for large volumes of data and may not be suitable for complex analytical queries.
Data Warehouses
Data warehouses, on the other hand, are repositories that consolidate data from multiple sources into a centralized, structured format for reporting and analysis. They typically follow a dimensional model and provide a historical view of data, allowing organizations to analyze trends and make informed decisions. Data warehouses are optimized for complex queries and aggregations across large datasets. They provide a single source of truth and maintain data integrity through data cleansing and transformation processes. However, data warehouses are often designed with a predefined schema, which can make accommodating new data sources or changing business requirements more challenging.
A read-only replica of the original database is often a simple cheap equivalent to a data warehouse for small reporting applications.
Data Lakes
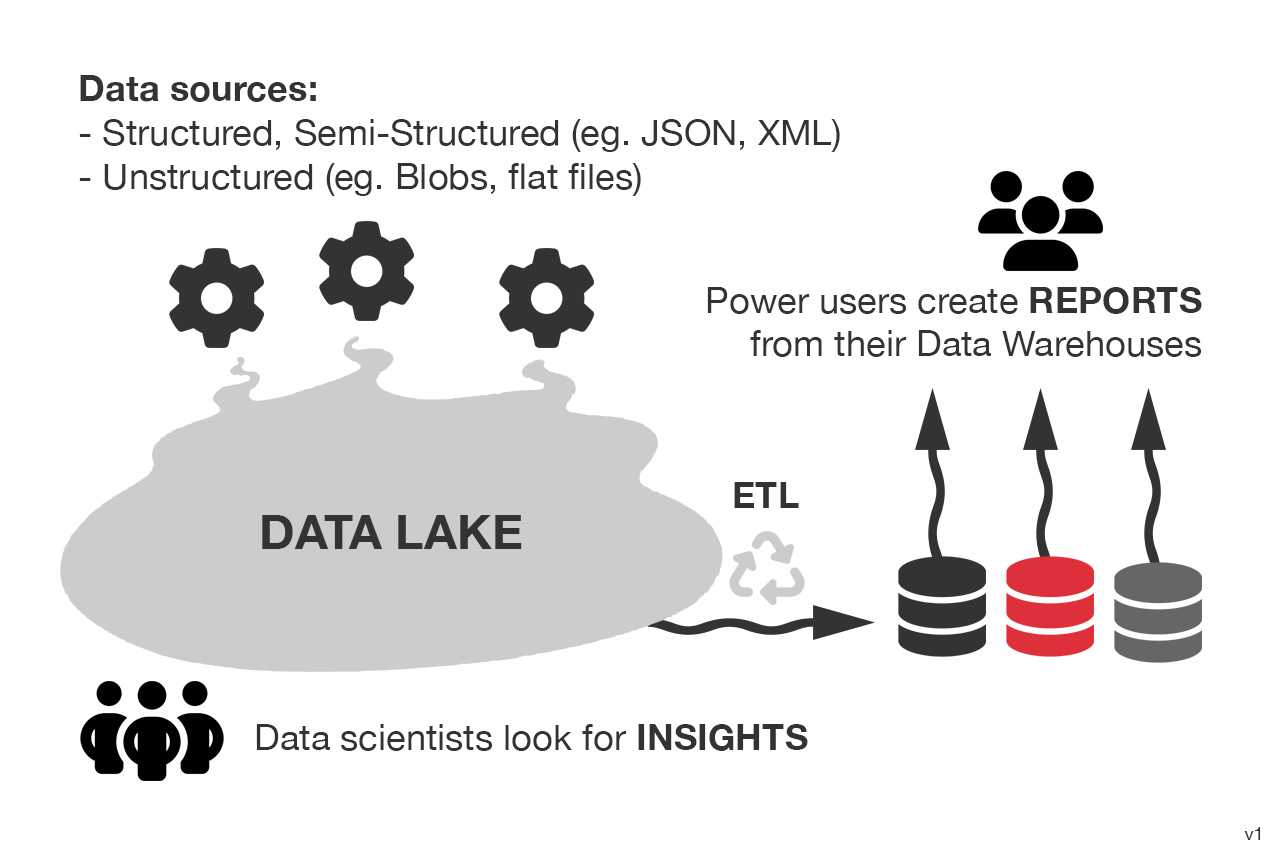
Data lakes are vast repositories that store data in its raw and unprocessed form, without a predefined structure. They can store structured, semi-structured, and unstructured data, such as text files, images, or social media posts. Data lakes offer flexibility and scalability, allowing organizations to store massive amounts of data from various sources. They are suitable for exploratory analysis and data discovery since data can be transformed and processed as needed. However, data lakes can become a "data swamp" without proper governance and metadata management. The lack of structure and schema can lead to data quality issues and make it harder to extract meaningful insights without additional processing.
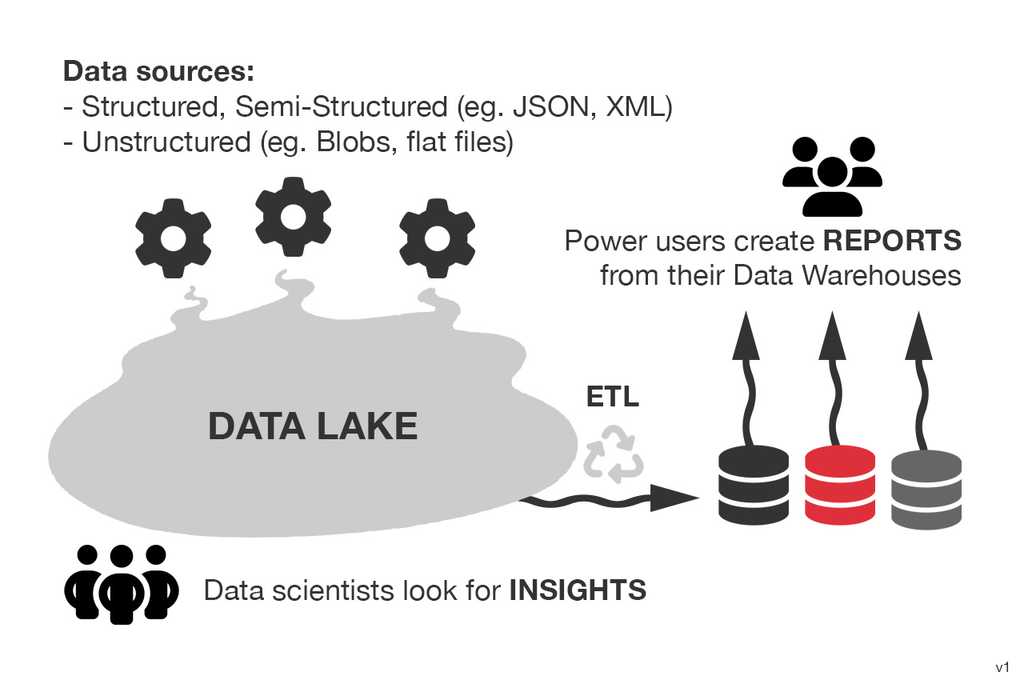
Things to consider
- When building reporting solutions that read from the original data store, take care when deciding on the refresh schedule. You'll need to balance timeliness vs cost on the system being read from. If the refresh is very expensive, try and run it out of hours to avoid affecting the application's users.
- For small applications adding a read only replica of the main database is a much simpler and more cost effective alternative to a data warehouse. It avoids the reporting queries affecting the live database. It is typically cheaper than a data warehouse, a data-lake is often the cheapest solution infrastructure wise.
Almost every piece of software requires a database - even the humble to-do app needs somewhere to store those tasks. Data is the lifeblood of many businesses, and the underlying databases are often the piece of infrastructure that live longest. But are you taking the time to really think about which database is the best fit for the job?
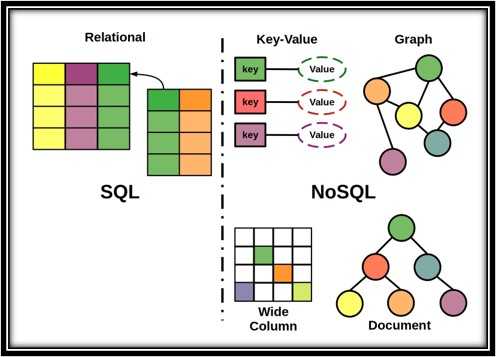
Figure: Which database is the best fit for the job? YouTube - Alex The Analyst gives a good summary of the differences between the main types of databases:
Video: SQL vs NoSQL | What is the Difference? (5 min)SQL databases
A relational database (often referred to as a SQL database) is a structured collection of data organized based on the principles of relational model theory. It consists of a set of interconnected tables, each representing a specific entity or concept. These tables contain rows (also known as records or tuples) that represent individual instances of the entity, and columns (also known as attributes or fields) that define the properties or characteristics of the entity. The relationships between tables are established through keys, which are used to link related data across multiple tables. The relational database management system (RDBMS) enables users to store, retrieve, and manipulate data efficiently using structured query language (SQL), providing a powerful and flexible solution for managing large volumes of data in a structured and organized manner.
✅ Benefits
- Data Integrity: Relational databases enforce data integrity through various mechanisms such as primary keys, foreign keys, and constraints. These ensure that data is accurate, consistent, and reliable, preventing duplicate or inconsistent records.
- Query Flexibility: Relational databases offer a rich and powerful querying language called SQL (Structured Query Language). SQL allows users to perform complex queries, aggregations, sorting, and filtering operations on the data. This flexibility enables users to retrieve information efficiently and derive valuable insights from the data.
- Scalability and Performance: Relational databases are designed to handle large volumes of data and can scale vertically (by adding more powerful hardware) or horizontally (by distributing data across multiple servers). With proper indexing and optimization techniques, relational databases can deliver high-performance query execution even with extensive data sets.
❌ Challenges
- Fixed Schema: Relational databases require a predefined schema that defines the structure and relationships of tables. Once the schema is set, it can be challenging to modify it without affecting existing data or applications. This lack of flexibility can be a limitation when dealing with rapidly evolving or unstructured data.
- Performance Overhead: Relational databases impose certain overhead due to their complex architecture and features. Joining multiple tables, enforcing constraints, and maintaining data integrity can sometimes impact performance, especially when dealing with complex queries or high transaction volumes.
- Scaling Limitations: While relational databases can scale horizontally by distributing data across multiple servers, there are practical limits to their scalability. As the data volume and transaction load increase significantly, scaling a relational database can become challenging and may require additional architectural considerations or specialized technologies.
NoSQL databases
A NoSQL (Not Only SQL) database is a non-relational database that provides a flexible and scalable approach to storing and managing data. Unlike traditional relational databases, NoSQL databases do not rely on fixed schemas and tabular structures. Instead, they use various data models, such as key-value, document, columnar, or graph, to organize and store data based on specific requirements. NoSQL databases are designed to handle large amounts of unstructured or semi-structured data and can scale horizontally by distributing data across multiple nodes or servers. They offer high performance and flexibility, allowing for agile development and easy scalability. However, NoSQL databases may sacrifice certain features of relational databases, such as strict data consistency or complex querying capabilities, in favor of improved scalability and performance in certain use cases.
Some of the main flavours of NoSQL databases are:
- Document
- KeyValue
- Blob
- Graph
✅ Benefits
- Scalability and Flexibility: NoSQL databases excel in handling large-scale and distributed data. They provide horizontal scalability by allowing data to be distributed across multiple servers or nodes, which enables efficient handling of high volumes of data and high traffic loads. Additionally, NoSQL databases offer flexibility in terms of data model and schema, allowing for easy adaptation to evolving data structures and requirements.
- High Performance: NoSQL databases are optimized for performance and can handle massive amounts of data with fast read and write operations. They are designed to achieve high throughput and low latency, making them suitable for use cases that demand real-time data processing, such as web applications, IoT, and streaming platforms.
- Schemaless Nature: Unlike relational databases that enforce rigid schemas, NoSQL databases are schemaless or have a flexible schema. This means that data can be stored without a predefined structure, allowing for easy handling of unstructured or semi-structured data. The absence of a fixed schema provides agility in development and allows for faster iteration and adaptation to changing data requirements.
❌ Challenges
- Limited Querying Capabilities: NoSQL databases typically offer limited querying capabilities compared to relational databases. They may lack complex join operations or the ability to perform ad-hoc queries efficiently. This can be a drawback when dealing with complex data relationships or when a wide range of query types is required.
- Data Consistency: NoSQL databases often prioritize scalability and performance over strict data consistency. In certain NoSQL models, such as eventual consistency, there might be a delay in propagating changes across all replicas, which can result in data inconsistencies in distributed systems. Ensuring data consistency in NoSQL databases may require additional application-level logic or trade-offs in terms of availability or performance.
- Learning Curve and Tooling: NoSQL databases often have a learning curve associated with their specific data models and query languages. Developers and administrators may need to learn new concepts and tools to effectively work with NoSQL databases. Additionally, the tooling and ecosystem around NoSQL databases may not be as mature or widely adopted as those for relational databases, which can impact development and operational processes.
A Data Warehouse is a centralized repository of data that is used for analysis and reporting, providing organizations with valuable insights to support decision-making processes. A Data Warehouse can offer significant benefits, so understanding its appropriate use cases and limitations is essential.

Data Warehouses act as a central repository that consolidate vast amounts of data from transactional systems, operational databases, external sources, and more. This consolidated data is then transformed and optimized for efficient reporting, analytics, and business intelligence purposes.
Video: Introduction to Data Warehouses (3 min)Basic (video above) - [YouTube: Cody Baldwin] gives a good overview of data warehouses, and why you'd want to build one.
Advanced - [YouTube: Azure Synapse Analytics] If you want to see an example, take a look at the video The Ultimate Data Warehouse experience in Microsoft Fabric (8 min) which shows how you can create a data warehouse in Microsoft Fabric.
✅ When to use a Data Warehouse
- Complex Analytical Reporting: Data Warehouses excel at handling complex queries and generating comprehensive reports across different dimensions of the data. If your organization requires in-depth analysis, trend identification, and complex reporting on large volumes of historical and real-time data, a Data Warehouse can be a valuable asset.
- Decision Support: When making strategic decisions based on data-driven insights, a Data Warehouse provides a reliable foundation. It enables the integration of data from multiple sources, which allows for a comprehensive view of the organization's operations, customers, and market trends. With a Data Warehouse, you can derive meaningful business intelligence and support decision-making processes effectively.
- Data Integration: If your organization deals with disparate data sources such as databases, spreadsheets, files, or external systems, a Data Warehouse offers a unified platform for integrating and harmonizing the data. It enables data cleansing, transformation, and consolidation, ensuring consistency and accuracy across various data sets.
- Historical Analysis: Data Warehouses retain historical data over extended periods, enabling retrospective analysis and trend identification. This capability is particularly useful for businesses that require insights into long-term performance, customer behavior, market trends, and forecasting.
❌ When not to use a Data Warehouse
- Real-time Transactional Processing: Data Warehouses are not suitable for real-time transactional processing where immediate response and low-latency data access are critical, as the data will often need to be cleaned or transformed (typically as a part of the ETL stage) before it can be used. Operational databases or other specialized systems are more suitable for such use cases.
- Small-scale Data Storage: If your organization deals with relatively small volumes of data that don't require extensive integration, analysis, or long-term historical retention, a Data Warehouse may introduce unnecessary complexity and overhead. In such cases, simpler data storage and retrieval solutions might suffice.
- Temporary Data Analysis: If you only need to perform ad hoc analysis on short-lived datasets, it may be more efficient to use other data analysis tools or platforms that don't involve building and maintaining a Data Warehouse.
Example
The business Northwind Chips & Cream sells hot chips and ice cream from their fleet of food trucks, operating across Australia.
The company wants to analyze its sales data across geographic locations and weather factors. They want to optimize their food truck distribution according to the highest grossing suburbs in each city for each day's conditions.
- The company's sales data is stored in an Accounting system (ACME).
- The trucks' locations are stored in a Fleet Management Library (FML).
- The weather data comes from the country's weather API (BOM).
A Data Warehouse is a compelling recommendation, because:
- Analytical goals are clearly defined
- Time variant data is used
- Daily forecasts incentivize automation
- Disparate data sources require aggregation
- No real-time data ingestion required
How to create a Data Warehouse
Creating your own data warehouse involves several key steps. Here's a general overview of the process:
1. Define Business Goals and Objectives
The first step is to clearly define the business goals and objectives that the Data Warehouse will support. This involves understanding the specific analytical and reporting requirements of the organization. Identify the key areas where data insights can drive value, such as improving operational efficiency, enhancing customer experience, or enabling strategic decision-making. By aligning the Data Warehouse project with the business goals, you ensure that it addresses the specific needs of the organization.
2. Conduct Data Assessment
Conducting a thorough data assessment is crucial to understand the current state of data within the organization. This step involves identifying the sources of data, data quality issues, data formats, data volume, and data integration requirements. Assessing the existing data infrastructure helps identify any gaps or inconsistencies that need to be addressed before implementing a Data Warehouse. It also helps in understanding the scope and complexity of data integration efforts required for successful implementation.
3. Develop a Data Warehouse Strategy and Architecture
After defining business goals and assessing data, the next step is to develop a comprehensive Data Warehouse strategy and architecture. This involves determining the appropriate architecture for the Data Warehouse, including decisions related to data modeling, data extraction, transformation, loading processes, and data storage. Consider factors such as scalability, performance, security, and future growth requirements. Additionally, establish a governance framework for data management, including data ownership, access controls, and data privacy considerations. Developing a clear strategy and architecture provides a roadmap for the implementation of the Data Warehouse and ensures its alignment with the organization's long-term goals.
Popular Data Warehouse products
- Microsoft Fabric
- Azure Synapse Analytics
- Amazon Redshift
- Google BigQuery
- Snowflake
- (On prem) Microsoft SQL Server
- (On prem) SQL Server Analysis Services
Remember, the decision to use a Data Warehouse should be based on the specific needs and requirements of your organization. Consider factors such as data volume, complexity, analytical needs, and long-term data retention before opting for a Data Warehouse solution.
In today's data-driven world, businesses face the challenge of managing and extracting insights from vast and diverse datasets. But how can businesses leverage the power of their data to gain a big picture view of their operation and make informed business decisions?
Welcome to Data Lakes.
A Data Lake is a centralized repository that stores vast amounts of raw, unprocessed data from various sources. It is designed to accommodate structured, semi-structured, and unstructured data in its native format, without the need for upfront data transformation or schema definition. The concept of a Data Lake emerged as a response to the limitations of traditional data warehousing approaches.
Basic - @AltexSoft gives a walk through of the data engineering process and how it would evolve in an organization:
Video: How Data Engineering Works (14 min)In a Data Lake, data is stored in its original form, such as CSV files, log files, sensor data, social media posts, images, videos, or any other data format. This raw data is often referred to as "big data" due to its volume, variety, veracity, and velocity. The Data Lake allows organizations to store and analyze this diverse range of data without imposing a predefined structure or format on it.
Key characteristics
- Centralized Repository: Data from multiple sources is ingested and stored in a single location, enabling easy access and exploration.
- Schema on Read: Unlike traditional data warehouses that enforce a schema upfront, Data Lakes allow for flexible schema definition during data retrieval or analysis. This enables data exploration and analysis without the need for extensive data transformation beforehand.
- Scalability: Data Lakes are built to scale horizontally, accommodating the growing volume of data as well as the increasing demands for processing power.
- Data Variety: Data Lakes accept and store various data formats, including structured, semi-structured, and unstructured data, allowing organizations to leverage diverse data sources.
- Storage Cost: Data Lakes typically use low-cost storage, as computations are done in batches or ad hoc, whereas a database/warehouse has its storage tightly coupled to its computational costs (as well as utilizing higher-cost storage).
- Data Exploration and Analytics: With the raw data stored in a Data Lake, organizations can apply various data processing and analytics techniques to extract insights, discover patterns, and derive value from the data.
- Data Governance and Security: It is crucial to implement proper governance policies and security measures to ensure data quality, privacy, and compliance within the Data Lake environment.
📈 Store now, analyze later
Perhaps the biggest point of differentiation between a Data Lake and a data warehouse, is the warts-and-all approach to its data capture. A data warehouse will typically have a very defined set of objectives that it's built to achieve, and the data it stores is hand-picked from various sources specifically for those purposes (via a process called ETL, or Extract, Transform, Load). This transformed data is great for delivering on its specific objectives, but will not be able to provide any meaningful answers to questions outside of its intended scope.
A Data Lake is less concerned with curating data to meet a given objective, and instead provides a centralized pool of data that can queried in many different ways later (via ELT, or Extract, Load, Transform). As it contains raw data, data scientists and engineers are able to invent new ways of reading and analyzing that data on demand.
🤢 Data swamps
Data swamps occur when adequate data quality and data governance measures are not implemented.
Given the flexibility of a Data Lake's storage abilities, a business is often enticed to throw every bit of data into it without due thought or consideration to organization or appropriate cataloguing. This can turn a Data Lake into a data swamp which makes any meaningful analysis later incredibly difficult.
Remember - great insights come from great data, and great data comes from strong governance!
Scenario
Imagine you work at Northwind. They have all these systems:
- GitHub/Azure DevOps – issues, commits, etc.
- Billing - Timesheets, Client invoices, etc
- CRM – Projects, skills, technologies, sales, leads, etc.
- Accounting – Business expenses, client payment receipts, payment dates, etc.
- Office automation logs – employee arrival/leave times, device usage, security alerts, etc.
- Websites – traffic, analytics, etc.
Comment below for what you think would be:
- What cool question would you ask this data? Be creative!
- How many systems would you be interacting with?
- Would you need a Data Lake or Data Warehouse?
🔨 Building your Data Lake
There are a few options to set up a Data Lake.
- Azure Data Lake (reccommended)
-
Microsoft Fabric Lakehouse
- AWS Data Lake
- Google Cloud
- DIY Data Lake