Rules to Better Naming Conventions - 22 Rules
It's the most obvious - but naming conventions are so crucial to simpler code, it's crazy that people are so loose with them...
For Javascript / Typescript
Google publishes a JavaScript style guide. For more guides, please refer to this link: Google JavaScript Style Guide
Here are some key points:
- Use const or let – Not var
- Use semicolons
- Use arrow functions
- Use template strings
- Use uppercase constants
- Use single quotes
See 13 Noteworthy Points from Google’s JavaScript Style Guide
For C# Java
See chapter 2: Meaningful Names Clean Code: A Handbook of Agile Software Craftsmanship
For SQL (see Rules to Better SQL Databases)
Boolean Properties must be prefixed by a verb. Verbs like "Supports", "Allow", "Accept", "Use" should be valid. Also properties like "Visible", "Available" should be accepted (maybe not). See how to name Boolean columns in SQL databases.
public bool Enable { get; set; } public bool Invoice { get; set; }Bad example - Not using naming convention for Boolean Property
public bool Enabled { get; set; } public bool IsInvoiceSent { get; set; }Good example - Using naming convention for Boolean Property
Naming Boolean state Variables in Frontend code
When it comes to state management in frameworks like Angular or React, a similar principle applies, but with a focus on the continuity of the action.
For instance, if you are tracking a process or a loading state, the variable should reflect the ongoing nature of these actions. Instead of "isLoaded" or "isProcessed," which suggest a completed state, use names like "isLoading" or "isProcessing."
These names start as false, change to true while the process is ongoing, and revert to false once completed.
const [isLoading, setIsLoading] = useState(false); // Initial state: not loadingNote: When an operation begins, isLoading is set to true, indicating the process is active. Upon completion, it's set back to false.
This naming convention avoids confusion, such as a variable named isLoaded that would be true before the completion of a process and then false, which is counterintuitive and misleading.
We have a program called SSW CodeAuditor to check for this rule.
When creating WebAPIs for your applications, it is useful to keep the naming consistent all the way from the back-end to the front-end.
Table name: Employees Endpoint: /api/Users
Bad Example: The endpoint is different to the table name
Table name: Employees Endpoint: /api/Employees
Good Example: Table name is the same as the WebAPI endpoint
By making the endpoint name the same as the table name, you can simplify development and maintenance of the WebAPI layer.
In some circumstances you may not have direct control over the database, and sometimes you may be exposing a resource that doesn't have a meaningful analogue in the database. In these situations, it may make sense to have different endpoint names - if doing so will simplify development for consumers of your WebAPI endpoints.
Test Projects
Tests typically live in separate projects – and you usually create a project from a template for your chosen test framework.Because your test projects are startup projects (in that they can be independently started), they should target specific .NET runtimes and not just .NET Standard.A unit test project usually targets a single code project.
Project Naming
Integration and unit tests should be kept separate and should be named to clearly distinguish the two.This is to make it easier to run only unit tests on your build server (and this should be possible as unit tests should have no external dependencies).Integration tests require dependencies and often won't run as part of your build process. These should be automated later in the DevOps pipeline.
Test Project Location
Test projects can be located either:
- Directly next to the project under test – which makes them easy to find, or
- In a separate "tests" location – which makes it easier to deploy the application without tests included
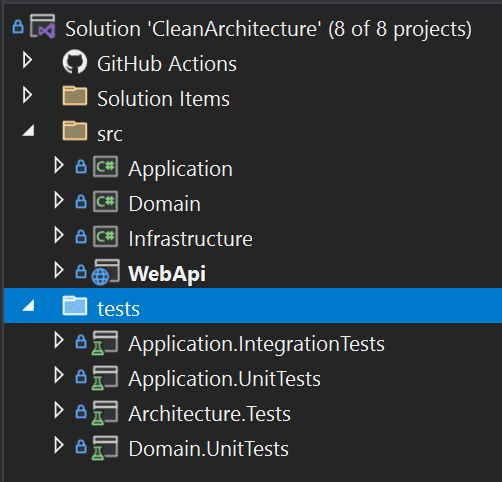
Figure: In the above project the tests are clearly placed in a separate location, making it easy to deploy to production without them. It’s easy to tell which project is under test and what style of tests will be found in each test project Source: github.com/SSWConsulting/SSW.CleanArchitecture
Naming Conventions for Tests
There are a few “schools of thought” when it comes to naming the tests themselves.Internal consistency within a project is important.It’s usually a bad idea to name tests after the class or method under test – as this naming can quickly get out-of-sync if you use refactoring tools – and one of the key benefits from unit testing is the confidence to refactor!
Remember that descriptive names are useful – but the choice of name is not the developer’s only opportunity to create readable tests.
- Write tests that are easy to read by following the 3 A's (Arrange, Act, and Assert)
- Use a good assertion library to make test failures informative (e.g. FluentAssertions or Shouldly)
- Use comments and refer to bug reports to document the “why” when you have a test for a specific edge-case
- Remember that the F12 shortcut will navigate from the body of your test straight to the method you’re calling
- The point of a naming convention is to make code more readable, not less - so use your judgement and call in others to verify your readability

Figure: Bad example - From the Test Explorer view you cannot tell what a test is meant to test just from its name Option 1: [Method/Class]_[Condition]_[ExpectedResult] (Recommended)
[Method/Class]_[Condition]_[ExpectedResult]Figure: The naming convention is effective – it encourages developers to clearly define the expected result upfront without requiring too much verbosity
Think of this as 3 parts, separated by underscores:
- The System Under Test (SUT), typically the method you're testing or the class
- The condition: this might be the input parameters, or the state of the SUT
- The expected result, this might be output of a function, an exception or the state of the SUT after the action
The following test names use the naming convention:
Withdraw_WithInvalidAccount_ThrowsException Checkout_WithCountryAsAustralia_ShouldAdd10PercentTax Purchase_WithBalanceWithinCreditLimit_ShouldSucceedFigure: Good example - Without looking at code, it's clear what the unit tests are trying to do
Option 2: [Given]_[When]_[Then]
[Given]_[When]_[Then]Figure: The naming convention is useful when working with Gherkin statements or BDD style DevOps
Following a Gherkin statement of:
GIVEN I am residing in Australia WHEN I checkout my cart THEN I should be charged 10% tax
This could be written as:
GivenResidingInAustralia_WhenCheckout_ThenCharge10PercentTaxConclusion
Remember, pick what naming method works for your team & organisation's way of working (Do you understand the value of consistency?). Then record it in your team's Architectural Decision Records
Resources
For more reading, the read the Microsoft guidance on Unit testing best practices
A list of other suggested conventions can be found here: 7 Popular Unit Test Naming Conventions.
Video: Hear from Luke Cook about how organizing your cloud assets starts with good names and consistency!


The scariest resource name you can find Organizing your cloud assets starts with good names. It is best to be consistent and use:
- All lower case
- Use kebab case (“-“ as a separator)
- Include a resource type abbreviation (so it's easy to find the resource in a script)
- Include which environment the resource is intended for i.e. dev, test, prod, etc.
- If applicable, include the intended use of the resource in the name e.g. an app service may have a suffix api
Azure defines some best practices for naming and tagging your resource.
Having inconsistent resource names across projects creates all sorts of pain
- Developers will struggle to find a project's resources and identify what those resources are being used for
- Developers won't know what to call new resources they need to create.
- You run the risk of creating duplicate resources... created because a developer has no idea that another developer created the same thing 6 months ago, under a different name, in a different Resource Group!
Keep your resources consistent
If you're looking for resources, it's much easier to have a pattern to search for. At a bare minimum, you should keep the name of the product in the resource name, so finding them in Azure is easy. One good option is to follow the "productname-environment" naming convention, and most importantly: keep it consistent!
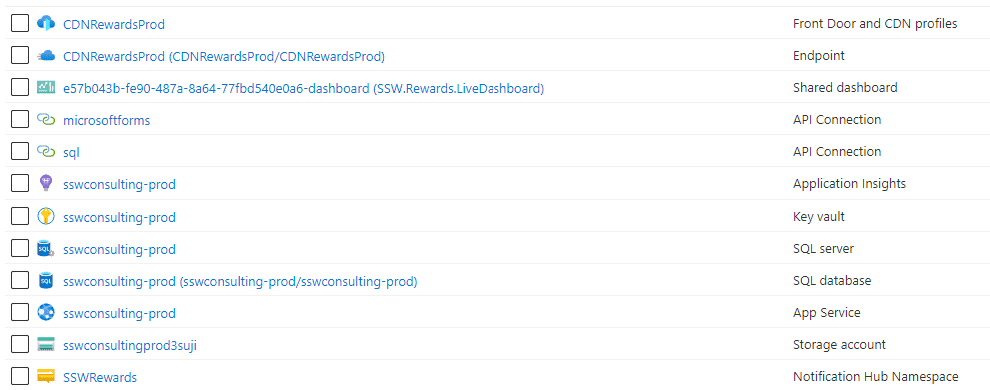
Bad Example - Inconsistent resource names. Do these belong to the same product? Name your resources according to their environment
Resource names can impact things like resource addresses/URLs. It's always a good idea to name your resources according to their environment, even when they exist in different Subscriptions/Resource Groups.
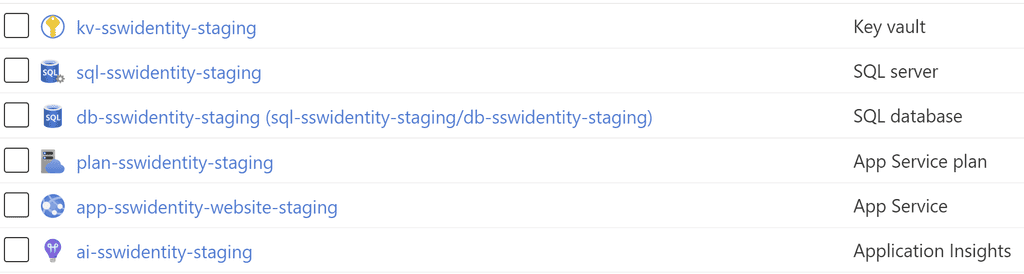
Good Example - Consistent names, using lowercase letters and specifying the environment. Easy to find, and easy to manage! Plan for the exceptions
Some resources won't play nicely with your chosen naming convention (for instance, storage accounts do not accept kebab-case). Acknowledge these, and have a rule in place for how you will name these specific resources.
Automate resource deployment
ClickOps can save your bacon when you quickly need to create a resource and need to GSD. Since we are all human and humans make mistakes, there will be times when someone is creating resources via ClickOps are unable to maintain the team standards to consistent name their resources.
Instead, it is better to provision your Azure Resources programmatically via Infrastructure as Code (IaC) using tools such as ARM, Bicep, Terraform and Pulumi. With IaC you can have naming conventions baked into the code and remove the thinking required when creating multiple resources. As a bonus, you can track any changes in your standards over time since (hopefully) your code is checked into a source control system such as Git (or GitHub, Azure Repos, etc.).
You can also use policies to enforce naming convention adherance, and making this part of your pipeline ensures robust naming conventions that remove developer confusion and lower cognitive load.
For more information, see our rule: Do you know how to create Azure resources?
Want more Azure tips? Check out our rule on Azure Resource Groups.

Naming your Resource Groups
Resource Groups should be logical containers for your products. They should be a one-stop shop where a developer or sysadmin can see all resources being used for a given product, within a given environment (dev/test/prod). Keep your Resource Group names consistent across your business, and have them identify exactly what's contained within them.
Name your Resource Groups as Product.Environment. For example:
- Northwind.Dev
- Northwind.Staging
- Northwind.Production
There are no cost benefits in consolidating Resource Groups, so use them! Have a Resource Group per product, per environment. And most importantly: be consistent in your naming convention.
Keep your resources in logical, consistent locations
You should keep all a product's resources within the same Resource Group. Your developers can then find all associated resources quickly and easily, and helps minimize the risk of duplicate resources being created. It should be clear what resources are being used in the Dev environment vs. the Production environment, and Resource Groups are the best way to manage this.

Bad example - A rogue dev resource in the Production RG Don't mix environments
There's nothing worse than opening up a Resource Group and finding several instances of the same resources, with no idea what resources are in dev/staging/production. Similarly, if you find a single instance of a Notification Hub, how do you know if it's being built in the test environment, or a legacy resource needed in production?

Bad example - Staging and Prod resources in the same RG Don't categorize Resource Groups based on resource type
There is no cost saving to group resources of the same type together. For example, there is no reason to put all your databases in one place. It is better to provision the database in the same resource group as the application that uses it.
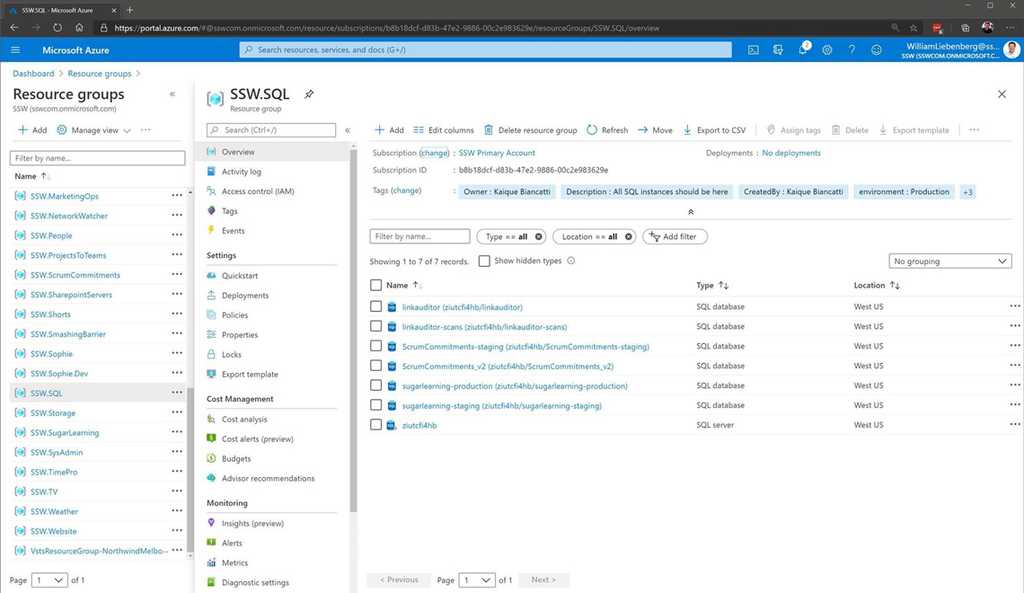
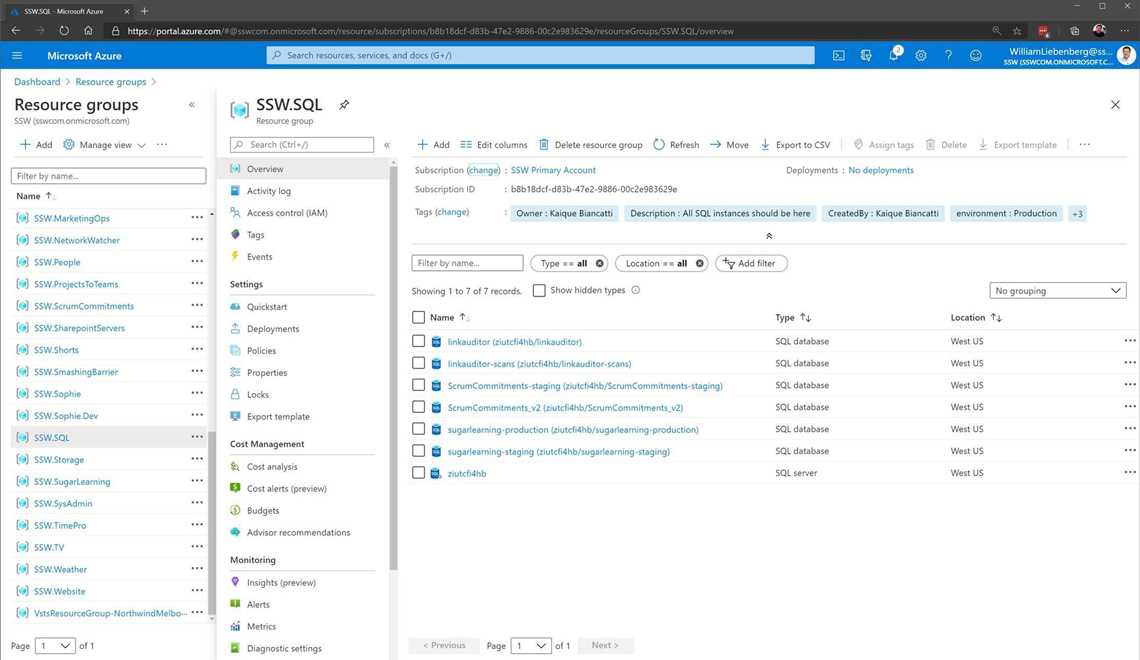
Figure: Bad example - SSW.SQL has all the Databases for different apps in one place 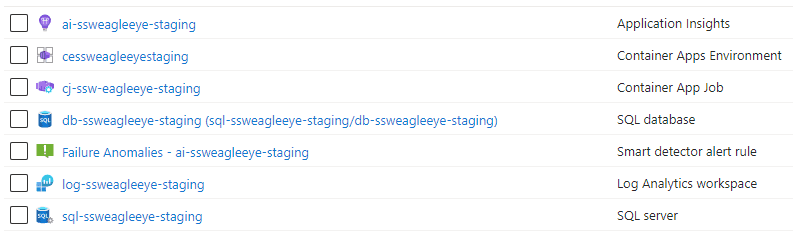
Figure: Good example (for all the above) - Resource Group contains all staging resources for this product To help maintain order and control in your Azure environment, applying tags to resources and resources groups is the way to go.
Azure has the Tag feature, which allows you to apply different Tag Names and values to Resources and Resource Groups:
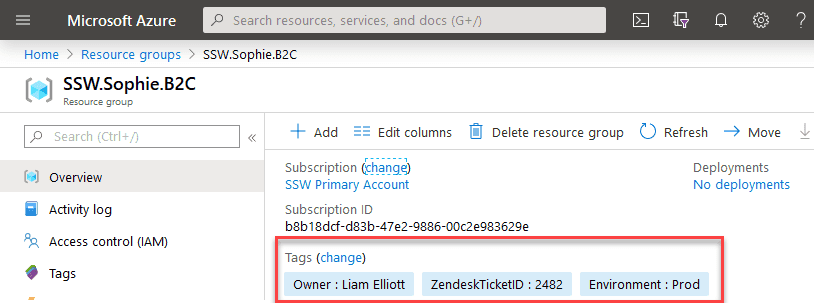
Figure: Little example of Tags in Resource Groups You can leverage this feature to organize your resources in a logical way, not relying in the names only. E.g.
- Owner tag: You can specify who owns that resource
- Environment tag: You can specify which environment that resource is in
Tip: Do not forget to have a strong naming convention document stating how those tags and resources should be named. You can use this Microsoft guide as a starter point: Recommended naming and tagging conventions.
If you use a strong naming convention and is using Tags to its full extent in Azure, then it is time for the next step.
Azure Policies is a strong tool to help in governing your Azure subscription. With it, you make it easier to fall in The Pit of Success when creating or updating new resources. Some features of it:
- You can deny creation of a Resource Group that does not comply with the naming standards
- You can deny creation of a Resource if it doesn't possess the mandatory tags
- You can append tags to newly created Resource Groups
- You can audit the usage of specific VMs or SKUs in your Azure environment
- You can allow only a set of SKUs within Azure
Azure Policy allow for making of initiatives (group full of policies) that try to achieve an objective e.g. a initiative to audit all tags within a subscription, to allow creation of only some types of VMs, etc...
You can delve deep on it here: https://docs.microsoft.com/en-us/azure/governance/policy/overview

Figure: Good Example - A fully compliant initiative in Azure Policy" Consistent naming is important so that users of your GitHub account can easily find what they are looking for and so that you appear professional.
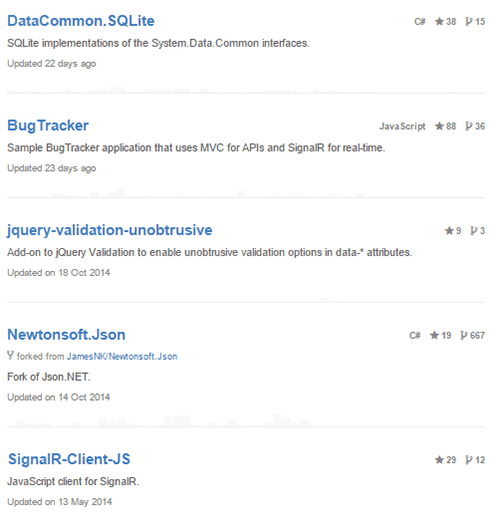
Figure: Bad example – Repository names are not consistently formatted 
Figure: OK example – Repositories are following the lower-cased hyphenated format that is common for open source projects 
Figure: Good example – Repository names are name-spaced in the format [CompanyName].[ProjectName] You should always follow a naming standard when naming your builds. This helps you identify their purpose at a glance.
The build name should have the following suffixes, depending on their purpose:
- .CI - For continuous integration builds. These are triggered automatically and do not deploy anywhere.
- .CD.[Environment] - For continuous delivery builds. These are triggered automatically and deploy to an environment. You should specify which environment it deploys to as well.
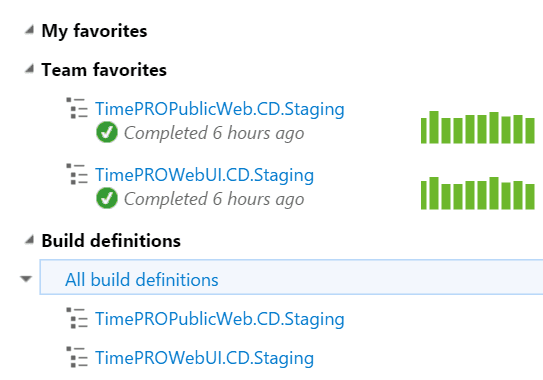
Good Example: We have two continuous delivery builds to our staging environment.
Generally, every client should have a dev and a test database, so the dev database needs to have the postfix "Dev" and the test database need to have the postfix "Test"(E.g. SSWCRMDev, SSWCRMTest). However, you don't need any postfix for the production database.
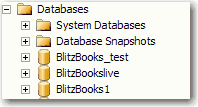
Figure: Bad Example - Database with bad names 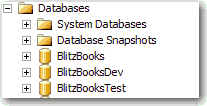
Figure: Good Example - Database with standard names This standard outlines the standard on naming objects within SQL Server. Use these standards when naming any object or fix if you find an older object that doesn't follow these standards.
Object Prefix Example Table Clients Column (PK) Id Column (FK) ClientId Temporary Table _zt _ztClients System Table _zs _zsDataVersion, _zsVersionLatest View vw, gy_ vwClientsWithNoPhoneW, gy_ClientsWithNoPhoneW Stored Procedure proc, gp_ procSelectClientsClientID, gp_SelectClientsClientID Trigger trg trgOrderIU Default* dft * dftToday * Rule rul rulCheckZIP User-Defined Datatype udt udtPhone User-Defined Functions udf udfDueDates Note: We never use defaults as objects, this is really an old thing that is just there for backwards compatibility. Much better to use a default constraint.
Other Links
- SQL Server Coding Standards - Part 1 by Steve Jones on SQL Server Central
This standard outlines the procedure on naming Relationships at SSW for SQL Server. Use this standard when creating new Relationships or if you find an older Relationship that doesn't follow that standard.
Do you agree with them all? Are we missing some? Let us know what you think.
Syntax
Relationship names are to have this syntax:
[PrimaryTable] - [ForeignTable]
[ 1 ] - [ 2 ][1] The table whose columns are referenced by other tables in a one-to-one or one-to-many relationship.Rather than accepting the default value i.e. ClientAccount_FK01 that is given from upsizing.
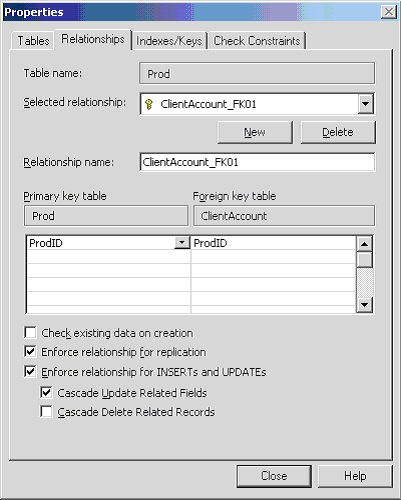
Figure: Bad Example - using the default relationship name We recommend using Prod-ClientAccount.
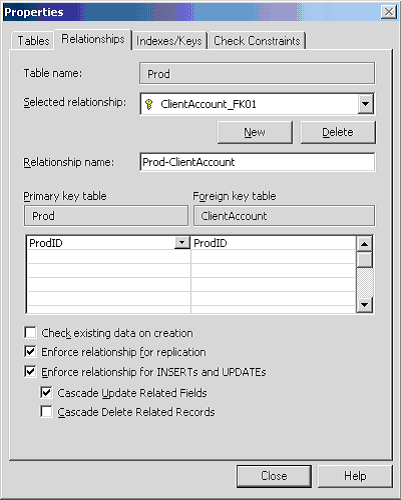
Figure: Good Example - using a more descriptive relationship name The good thing is when you look at the relationship from the other side it is there as well.

Figure: Relationship name shown on the other table We also believe in using Cascade Updates - but never cascade deletes.
This standard outlines the standard on naming Stored Procedures within SQL Server. Use these standards when creating new Stored Procedures or if you find an older Stored Procedure that doesn't follow these standards within SSW.
Note: Stored Procedures will run fractionally slower if they start with a prefix of sp_ This is because SQL Server will look for a system stored proc first. Therefore we never recommend starting stored procs with a prefix of sp_ Do you agree with them all? Are we missing some? Let us know what you think.
Syntax
Stored Procedure names are to have this syntax:[proc] [MainTableName] By [FieldName(optional)] [Action][ 1 ] [ 2 ] [ 3 ] [ 4 ][1] All stored procedures must have the prefix of 'proc'. All internal SQL Server stored procedures are prefixed with "sp_", and it is recommended not to prefix stored procedures with this as it is a little slower.[2] The name of the table that the Stored Procedure accesses.[3] (optional) The name of the field that are in the WHERE clause. ie. procClientByCoNameSelect, procClientByClientIDSelect[4] Lastly the action which this Stored Procedure performs.
If Stored Procedure returns a recordset then suffix is 'Select'.If Stored Procedure inserts data then suffix is 'Insert'.If Stored Procedure updates data then suffix is 'Update'.If Stored Procedure Inserts and updates then suffix is 'Save'.If Stored Procedure deletes data then suffix is 'Delete'.If Stored Procedure refreshes data (ie. drop and create) a table then suffix is 'Create'.If Stored Procedure returns an output parameter and nothing else then make the suffix is 'Output'.
ALTER PROCEDURE procClientRateOutput @pstrClientID VARCHAR(6) = 'CABLE', @pstrCategoryID VARCHAR(6) = '<All>', @pstrEmpID VARCHAR(6)='AC', @pdteDate datetime = '1996/1/1', @curRate MONEY OUTPUT AS -- Description: Get the $Rate for this client and this employee -- and this category from Table ClientRate SET @curRate = ( SELECT TOP 1 Rate FROM ClientRate WHERE ClientID=@pstrClientID AND EmpID=@pstrEmpID AND CategoryID=@pstrCategoryID AND DateEnd > @pdteDate ORDER BY DateEnd ) IF @curRate IS NULL SET @curRate = ( SELECT TOP 1 Rate FROM ClientRate WHERE ClientID=@pstrClientID AND EmpID=@pstrEmpID AND CategoryID='<ALL>' AND DateEnd > @pdteDate ORDER BY DateEnd ) RETURNFigure: Good Example - stored proc that returns only an output parameter
Select 'procGetRate' or 'sp_GetRate' Insert 'procEmailMergeAdd'
Figure: Bad Example
'procClientRateSelect' 'procEmailMergeInsert'
Figure: Good Example
Keeping track of CRM customization changes is just as difficult as back-end database changes. We have a rule Is a Back-end structural change going to be a hassle? which provide you an example how you should keep track of back-end changes. You can apply this rule to CRM changes and use a naming convention on each customization backup file to identify and keep track of your changes.
Your customization file name should be:
[IncrementalNumber]_[Entity]_[Date].zip, for example: 001account29042009.zip
The file's name can tell you which entity you made changes and which date the changes were made. The incremental number will provides us step by step instruction on how to produce the current CRM system from a vanilla Microsoft Dynamics CRM.
CRM2011 has significant improvements in this area with Solutions. In CRM 2011 we use versioned solutions along with source control.
When naming documents and images, use descriptive words and kebab-case (where you separate words with hyphens) to make your files more easily discoverable.
✅ Choose the right words
The file name and its title is regarded more highly by search than the content within documents. Also, the file name is what is displayed in search results, so by making it descriptive you are making it easier for people to identify the purpose of your document.
Once you have chosen the best words, make it readable and consistent in formatting:
❌ Avoid spaces
Monthly Report.docx
Figure: Bad example - File name using spaces to separate words
As far as search goes, using spaces is actually a usable option. What makes spaces less-preferable is the fact that the URL to this document will have those spaces escaped with the sequence %20. E.g. sharepoint/site/library/Monthly%20Report.docx. URLs with escaped spaces are longer and less human-readable.
Know more on Do you remove spaces from your folders and filename?
❌ Avoid CamelCase
MonthlyReport.docx
Figure: Bad example - File name using CamelCase doesn't have spaces but also doesn't contain any separators between words
This is a popular way to combine words as a convention in variable declarations in many coding languages, but shouldn't be used in document names as it is harder to read. Also, a file name without spaces means that the search engine doesn't know where one word ends and the other one begins. This means that searching for 'monthly' or 'report' might not find this document.
❌ Avoid Snake_Case
Monthly_Report.docx
Figure: OK example - Underscored (Snake_Case) URLs have good readability but are not recommended by Google
Underscores are not valid word separators for search in SharePoint, and not recommended by others. Also, sometimes underscores are less visible to users, for example, when a hyperlink is underlined. When reading a hyperlink that is underlined, it is often possible for the user to be mistaken by thinking that the URL contains spaces instead of underscores. For these reasons it is best to avoid their use in file names and titles.
✅ Use kebab-case
monthly-report.docx
Figure: Good Example - File name uses kebab-case (dashes to separate words)
A hyphen (or dash) is the best choice, because it is understood both by humans and all versions of SharePoint search.
You may use Uppercase in the first letter in Kebab-Case, however it's important to keep consistency
Extra
- Add relevant metadata where possible
If a document library is configured with metadata fields, add as much relevant information as you can. Metadata is more highly regarded by search than the contents within documents, so by adding relevant terms to a documents metadata, you will almost certainly have a positive effect on the relevance of search results.
- Ensure filenames are unique when tracking files with Git
Within a team, there may be a mix of operating systems being used by its members. For users on MacOS or other OS's that have case-sensitive filenames, it's crucial to ensure that filenames are unique. For example, don't use 'File.txt' if 'file.txt' already exists. This is especially important if these files are being tracked with Git, as it can cause issues for users on Windows, which has case-insensitive filenames.
Client Teams should be prefixed with “Client –“ so it is easier to identify them.

Bad Example: Client team without the "Client –" prefix 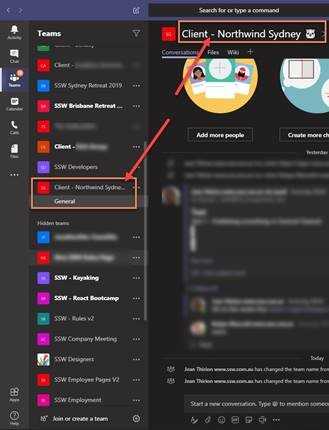
Good Example: Well prefixed Teams make Client-related teams easier to identify The use of standardized group names is a simple yet crucial step towards easier management. Reducing the number of AD groups will make it simpler to manage and allow new staff to figure out what's what faster.
You can save yourself countless confused conversations by standardizing AD Group Names.
Warning: Be very careful if you are renaming groups - permissions can break, especially if the group is sync'd to Entra ID (formerly Azure AD).
For example, this is a list of AD groups associated with products:
SSWSugarLearningAlerts
Alerts CodeAuditor
SEC_SSW-LinkAuditor-Devs
timepro-devsFigure: Bad Example – With no consistency, it is difficult to know the correct name for an AD group
SSWSugarLearningAlerts
SSWCodeAuditorAlerts
SECSSWLinkAuditorDevs
SECSSWTimeProDevsFigure: Good Example – By standardizing the names of AD groups it saves confusion
::: infoNote: For large organizations, a better way is to use a type of group (eg. Local or Global)... then the entity it is associated to… then the resource (or service).
Examples:
- L-LocalGroupName-SYD-EntityName-SP-Sharepoint- becomes L-SYD-SP-SSW-Users
- G-GlobalGroupName-SYD-EntityName-SP-Sharepoint- becomes G-SYD-SP-SSW-Users
:::
Types of groups
It is also important to differentiate between Distribution groups (or other groups with mail enabled), and Security groups. Distribution groups should have names that are clear, that work well for an email address - for example, SSWRulesDevs. Security groups should have the prefix It is SEC_, so that it is clear they are security groups (and cannot receive email), e.g. SEC_VPNUsers.
When we configure networks we give all computers in the company a naming theme like:
- Buildings
- Cars
- Countries
- Colours
- Fruits
- Vegetables, etc
At SSW we have adopted the animal kingdom.
Figure: We name the PCs and label them - this one is "Great Pyrenees" While you are attaching the label, it is also a good idea to affix a business card to the underside of the computer. This way if you lose your machine, anyone who finds it can easily contact you.
When you configure Hyper-V Clustering, each node will have upwards of 4 network adapters, some virtual and some physical. It is important to give these adapters meaningful names so you know what network adapter does what.
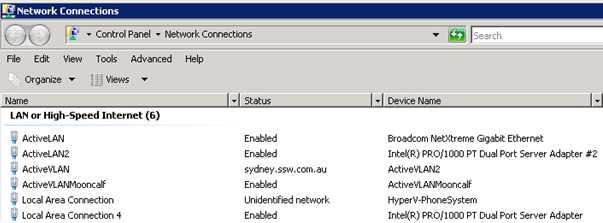
Figure: Bad Example - It makes it hard to know what network adapter does what if you don't have meaningful names 
Figure: Good example - As an example naming convention for network adapters on each node 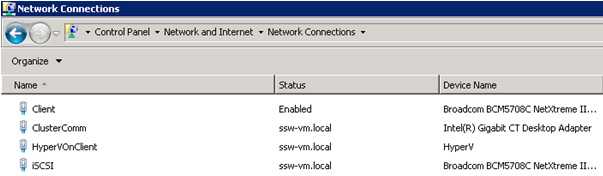
Figure: Good Example - It is easy to tell which network adapter does what when they have meaningful names When your Hyper-V environment is spread across multiple hosts and contains many Virtual Servers, it can get very confusing to find the one you are looking for amongst them all. This is why you should use a standard naming convention for all your Virtual machines.
Bad Example - How do you know what machine is what? The standard we use for Production Virtual Machine naming is as follows: NetBIOSName-ServiceName.
For example: Falcon-SCVMM.The standard we use for Development Virtual Machine naming is as follows: DEV-NetBIOSName-ServiceName-DeveloperInitials.
For example: DEV-demo2010a-SP2010MSInfoWorker-JL.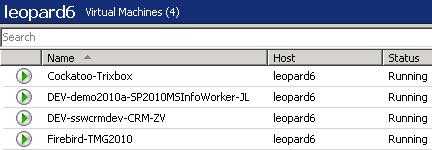
Good Example - It is easy to tell which VM is which when they are named to a standard When you look at the Service Calendar, you want to be able to see, at a glance, who is working on what.
To do this, the subject field of appointments should be as follows:
Client [Project] - Name[s]
The project name (in parentheses) is optional and only used if there is more than one project happening simultaneously.
You can have 1 or many names, depending on the booking.
Go to ACME Corp Work onsite for ACME Corp Mehmet working at ACME Corp
Figure: Bad example - all inconsistent and hard to read
ACME Corp - Mehmet ACME Corp - Mehmet, Dan ACME Corp (SharePoint) - Dan
Figure: Good Examples
The same format should also be used for leave requests (the same for normal calendar appointments/invitations).
Leave - Mehmet
Figure: Good Example
Related rules
- Do you realize the importance of a good email Subject?
- Appointments - Do you make sure your appointment has a good subject?